










Windowsを想定したローカル環境で高品質な画像生成ができる、Stable Diffusion。
オープンソースで開発・公開されているため、ある程度のスペックのPC(おもにGPUの性能が重要)を持っているなら誰でも無料で使えるのが魅力。
一方で・・・
 電化ねこ
電化ねこStable Diffusionってなんか難しそう…
と、使い始めるまでの敷居の高さに、導入を躊躇してしまっている人も少なくないことでしょう。
ここではそんなPCスキルに自信のない人でもStable Diffusionを導入できるよう、わかりやすい手順を記載した導入マニュアルを作ってみました。
手順に従って進めていけば、誰でもStable Diffusionを使い始めることができるので、ぜひ参考にしてもらえればと思います。
必要なPC環境
とはいえ、ある程度のPC環境が整っていないと、せっかくStable Diffusionの導入に成功しても、画像を生成することができません。
なので、事前に必要なPC環境についてチェックをしておきましょう。
具体的な構成例で、最低限動かせるラインと、快適に使えるラインを示しておきます。
最低限なんとか動かせるライン(解像度512×512程度を想定)
| CPU | Intel Core i5-8400 / AMD Ryzen 5 2600 以上 |
|---|---|
| メモリ | 8GB(推奨は16GB) |
| GPU | NVIDIA GTX 1660(VRAM 6GB) / NVIDIA RTX 2060(VRAM 6GB) |
| ストレージ | SSD推奨(空き20GB以上) |
快適に使えるライン(高解像度や拡張機能も楽しみたい)
| CPR | Intel Core i7-12700 / AMD Ryzen 7 5700X 以上 |
|---|---|
| メモリ | 16GB~32GB |
| GPU | NVIDIA RTX 3060(12GB) / RTX 3070(8GB)以上 |
| ストレージ | SSD(空き50GB以上) |
スペックは足りていましたか?
もし足りてないなら、PCをアップグレードさせるか、もしくはGoogle Colabなどのクラウドサービス(オンライン上で高性能GPUを一時的に借りる方法)を利用するか、Remote GPUレンタルサービス(安定的に使えるGPU環境を有料で借りる)などの方法もあるので、そういった方法も検討しましょう。
その他にも、Stable DiffusionのCPU版も存在しますが、とにかく動作が遅いため非推奨です。
その他にも、ConoHa AI Canvasなら、ブラウザ上でStable Diffusionを知識不要で簡単に利用できたりもします。

事前準備
Python3.10をインストール
解凍してインストーラーを実行
ダウンロードしてきたインストーラーを実行します。

インストーラーを実行する際には、「Add python.exe to PATH」のチェックを入れてから、「Install Now」をクリックします。(もし入れ忘れた場合は一度アンインストールしてやりなおしましょう。)

以下の画面が表示されたらインストール完了。 右下の「Close」で画面を閉じましょう。

Gitをインストール
続いて、公式サイトから「Git」をインストールします。
GitはStable Diffusionを最新の状態に保つためのツールです。 なくても大丈夫ですが更新が手間になるので、この時点であわせてインストールしておくのがおすすめです。
公式サイトからGitをダウンロード
Git公式サイトを開いたら、ハイライトの「Downloads」をクリック。

Downloadsページで「Windows」をクリック。

次のページの最上部にある「Click here to download」をクリックすると、最新バージョンのGitがダウンロードされます。

Gitのインストール
ダウンロードしてきたインストーラーを実行します。
多くの設定項目が表示されますが、すべての項目でそのまま「Next」を選んでインストールしてしまってOKです。

インストールが完了すると、右クリックのコンテキストメニューに以下の項目が表示されるようになります。(次の項目で使います)

Stable Diffusion Web UI(AUTOMATIC1111版)の導入
事前準備が整ったら、いよいよStable Diffusionを導入していきます。
Stable Diffusionをローカルで操作するために、AUTOMATIC1111版のWeb UIを利用するのがもっとも一般的かつわかりやすいです。 ブラウザ上で簡単にプロンプトを入力しながら画像生成できるようになります。
エクスプローラーを開き、Stable Diffusion Web UIをインストールしたいフォルダを開き、右クリックメニューから「Open Git GUI here」を選択しましょう。

以下のウィンドウが立ち上がるので、「Clone Existing Repository」をクリックしましょう。

次の画面で以下のように入力して「Clone」ボタンをクリックします。

| Source Location | https://github.com/AUTOMATIC1111/stable-diffusion-webui.git |
|---|---|
| Taget Directory | Stable Diffusion Web UIを保存する場所を選択 |
うまくいくと、指定したフォルダーの中に必要なファイル群が追加されます。
そうしたら、このウィンドウはもう閉じてしまってOK!

上で追加されたファイルの中から、「webui-user.bat」を選んで実行します。

以下のウィンドウが表示され処理が始まりますので、終わるまでじっと待機しましょう。
すべて終わるまでけっこうな時間がかかります。(数分~場合によっては数十分程度)

処理が完了すると自動でWeb UIが表示されます。
Web UIなので、ブラウザに以下の画面が表示されたら無事導入完了。

 よっしー
よっしー初回のみ時間がかかりますが、2回目以降はそこまで時間がかかりません
Stable Diffusionのモデルの準備
Stable Diffusionには、デフォルトで入っているモデルもありますが、配布されているモデルを入手し組み込むことで、さらに使い勝手が良くなります。
まずはモデルファイルダウンロード時の注意点から。
- Stable Diffusion v1.4, v1.5, 2x系など複数バージョンがあるが、v1.5が比較的使いやすくて対応ツールやガイドも豊富
- 通常、数GBの大きなファイルになるので、ダウンロードに時間がかかる可能性がある
- .ckpt 形式や .sefetensors 形式がある。安全性の観点から .safetensors 推奨(.ckpt 形式はリスクが高い)
Stable Diffusionモデルデータの入手場所
Stable Diffusionのモデルデータ(学習済みデータ)は、おもに以下のような場所で配布されています。
利用の際には、各モデルのライセンスや利用規約を事前にチェックしておくようにしましょう。
1.Hugging Face
URL:https://huggingface.co/models
さまざまなAIモデルをホスティングしている大手プラットフォーム。
Stable Diffusionの公式リポジトリや、それをベースにしたカスタムモデルを数多く公開。
2.Civitai
Stable Diffusion用のコミュニティ特化型プラットフォームとして人気が高まっている。
バニラのStable Diffusionに加えて、アニメ調やリアル系などテーマ別に細分化されたモデルやLoRA、Textual Inversionなども充実。
モデルのプレビュー画像や設定例を参照したり、ユーザーの評価やコメントでモデルの特徴がつかいみやすいのも特徴。
3.Stability AI 公式
URL(GitHub):https://github.com/Stability-AI
URL(公式サイト):https://stability.ai/
Stable Diffusionを開発しているStability AIの公式GitHubリポジトリ。
公式のウェイトファイル(モデル)へのリンクや、参考情報なども公開。
Civitaiからモデルデータを入手
ここでは、一番使い勝手のいい Civitai からモデルデータを導入していきます。
公式サイトを開いたら、画面上部のタブから「Models」を選択し、表示された一覧から入手したいモデルデータを選択。

あとはダウンロードアイコンをクリックすると、モデルのダウンロードがはじまります。
モデルをダウンロードするためには、Civitai にログインしておく必要がありますので、次の画面で新規アカウントを作成しておきましょう(Google経由で作るのがカンタン)

Stable Diffusionにモデルデータを配置
モデルデータ( .safetensors ファイル)のダウンロードが完了したら、以下の場所に配置します。
上で作成したWeb UIフォルダ/models/Stable-diffusion
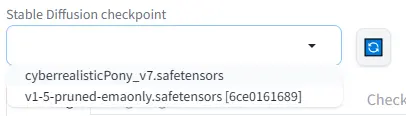
ファイルが移動できたら、Web UIの左上からモデルが選択できるようになります。
Stable Diffusionを日本語化
Stable Diffusionは、デフォルトの状態だと英語表示でわかりにくいので、まずは日本語化しましょう。
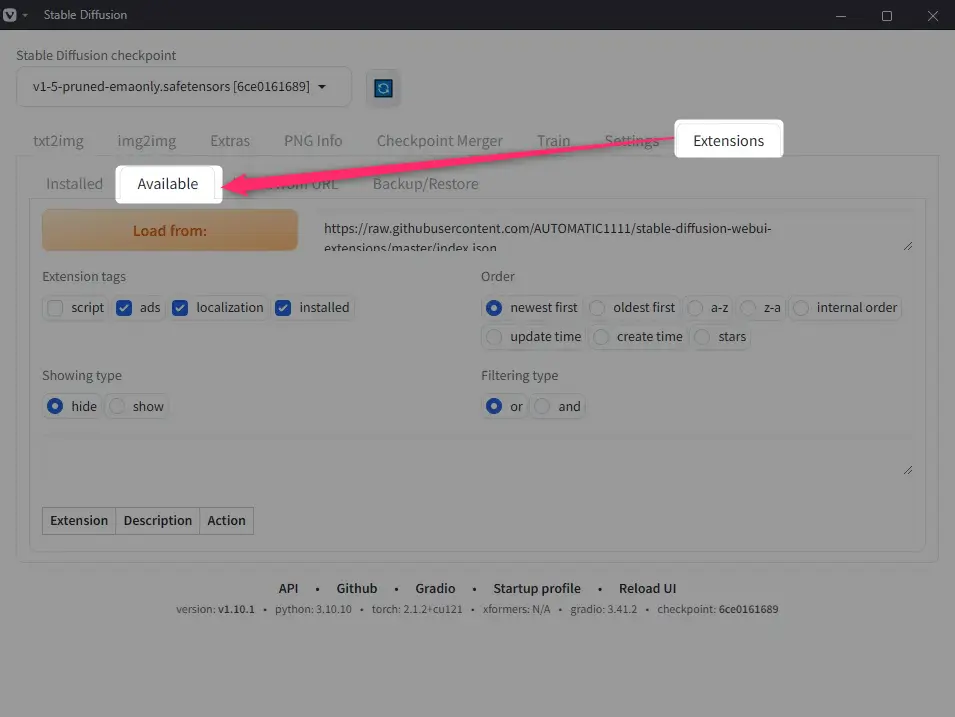
Web UIの画面で、「Extensions」→「Available」とタブを選択。
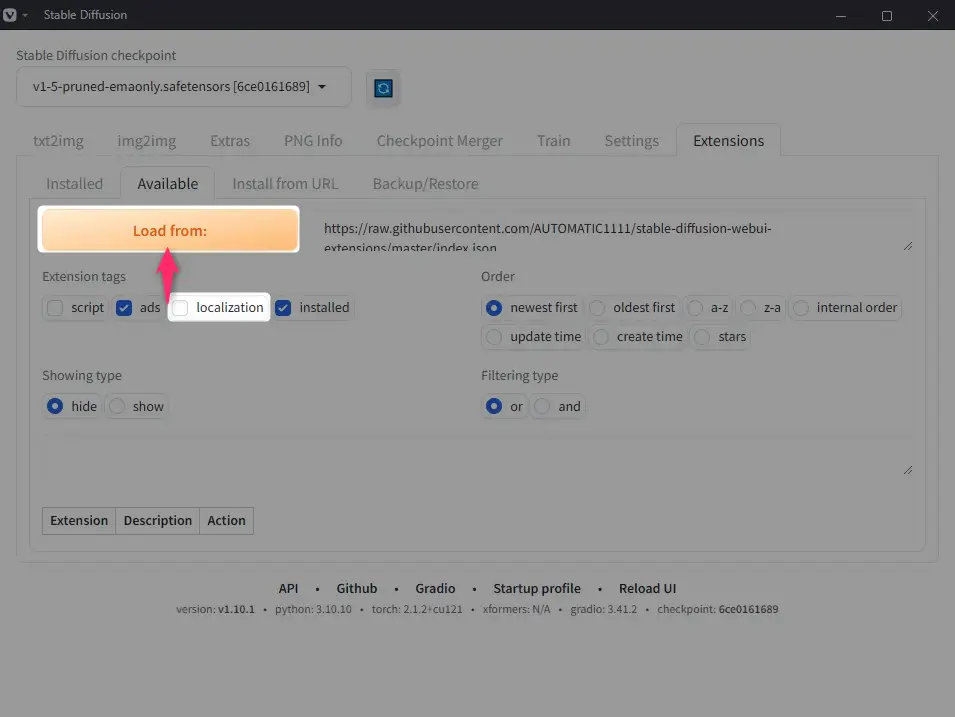
「localization」のチェックを外して「Load from:」をクリック。
画面を下にスクロールし「ja_JP Localization」を見つけて、右にある「Install」ボタンをクリック。(私の場合だとかなり下の方にありました)

「Settings」タブ → 左メニューより「User interface」をクリック。


「Localization」のドロップダウンメニューより、「ja_JP」を選択。(ない場合は右のリフレッシュボタンを押しましょう)

「Apply settings」をクリックしてから、「Reload UI」をクリック。

これで無事日本語化されました。 一気にわかりやすくなりましたね!

生成テストを行う
それでは、いよいよ画像の生成テストを行ってみましょう。
プロンプト(AIへの指示文)から画像を生成するには、「txt2img」を使います。
1.プロンプトを作成
プロンプトには、普通のプロンプトとネガティブプロンプトの2種類があります。
プロンプトには、生成したいイメージやスタイルを記述、ネガティブプロンプトには、逆に生成して欲しくない内容をそれぞれ入力しておきます。
Stable Diffusionは、日本語のプロンプトにも対応していますが、英語で入力したほうが精度が高い画像が生成されます。
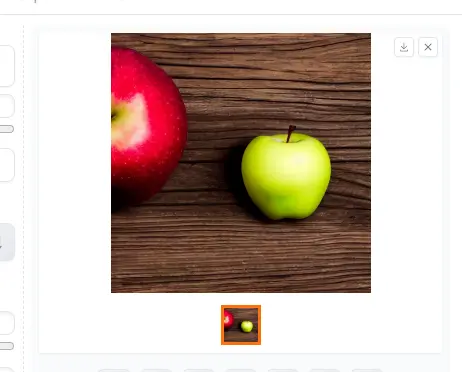
今回は、以下のプロンプトを入力してみました。
| プロンプト | a photo of an apple on a wooden table, award-winning photography, |
|---|---|
| ネガティブプロンプト | blurry, low quality, duplicate, bad anatomy |

2.生成パラメーターを設定
次に、サンプリング方法、Schedule type、画像の幅や高さなどを調整します。
今回は生成テストなので、わからなければとりあえずはそのままでOK。

3.生成ボタンをクリック
完了したら、あとは右の「生成」ボタンをクリックするだけ!

こんな感じで、指定したリンゴの画像が生成されました!(プロンプト和訳:木のテーブルの上のリンゴの写真)
さいごに
Stable Diffusionの環境構築から、実際に画像を生成するまでの流れを画像付きで解説しました。
最初に環境構築するまでは手数も時間もかかりますが、一旦セットアップが完了すれば以降はブラウザから手軽に高品質な画像を生成できるようになります。
さらに詳しいStable Diffusionの機能や、発展した使い方なんかは、また別の記事で解説しようと思います。
よっしー以下の記事のPollo AIだともっと簡単に画像生成ができますよ!















コメント